



Inside the Mind of Machines: A Simple Guide to Neural Networks
A beginner-friendly journey through how neural networks transform simple data into intelligent predictions — inspired by how the human brain learns.
Introduction
I was fascinated by the idea that machines can “learn” like humans. How can a computer recognize a face, translate a sentence, or even create art — just from data?
At first, the math behind it seemed intimidating. Terms like weights, gradients, and backpropagation sounded more like an alien language than a path to intelligence. But the deeper I delved, the more I realized something fundamental: neural networks mirror the basic principles of our brains.
Just as neurons in our brains connect and transmit signals, artificial neural networks do something similar — but with numbers instead of biology. Once I saw this parallel, everything started to make sense.
In this article, we’ll explore how neural networks actually work — from the perceptron to multi-layer learning — and uncover how machines “think” in their own mathematical way.
Context
Our main challenge was understanding what “learning” actually means for a machine.
Initially, I started with linear models — the simplest form of prediction. A model that predicts something based on a linear equation like s = Wx.
Here, W is a matrix of weights and x is the input (say, pixel values of an image). The output s is a score showing how confident the model is in its prediction.
For a dataset like CIFAR-10, each image is represented as a vector of 3072 numbers (32×32×3 pixels), and the output is a 10-dimensional score vector — one for each class (cat, dog, car, etc.).
This worked — but only for simple, straight-line patterns. The world isn’t linear. Images, sounds, and text are full of nonlinear, complex relationships. So we needed something that could go beyond straight lines — something that could learn curves, patterns, and layers of meaning.
That’s when we met the Perceptron — the simplest building block of a neural network.
Approach
Step 1: Understanding the Perceptron — The Digital Neuron
Biological Neuron
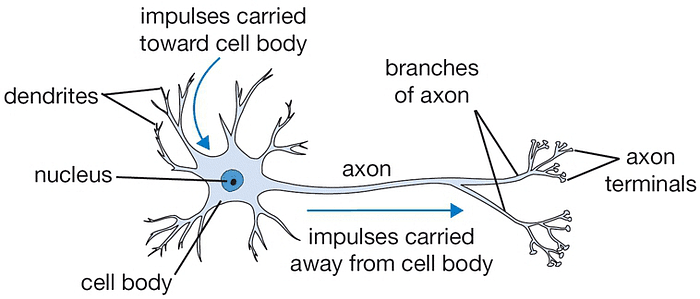
This fig shows Biological Neuron.
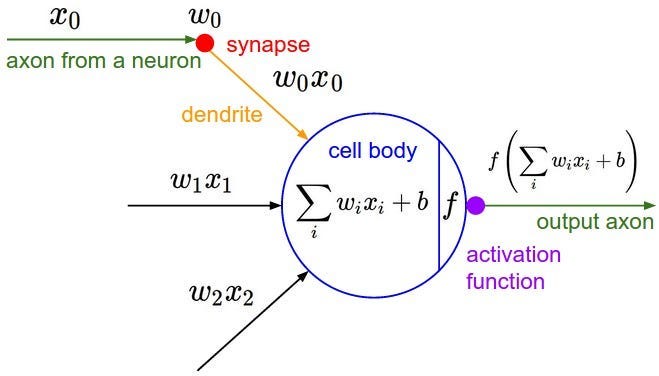
This fig shows Mathematical Neuron called Perceptron
The perceptron was my first “Aha!” moment. It’s a simple model inspired by how a biological neuron works.
In the brain, a neuron receives signals from other neurons, processes them, and fires an electrical signal if the input is strong enough. The perceptron works almost the same way.
It takes multiple inputs (like pixels of an image), multiplies each by a weight (its importance), adds them all up, and then applies a threshold — an activation function. If the total signal passes the threshold, the perceptron “fires” (outputs 1); otherwise, it stays silent (outputs 0).
Mathematically, it looks like this: y = f(Wx + b)
This tiny model can make decisions — like classifying whether an image is a cat or not — based on how it adjusts its weights during training.
Step 2: Building a Neural Network
The next step was stacking multiple perceptrons into layers. We started with a simple two-layer network:
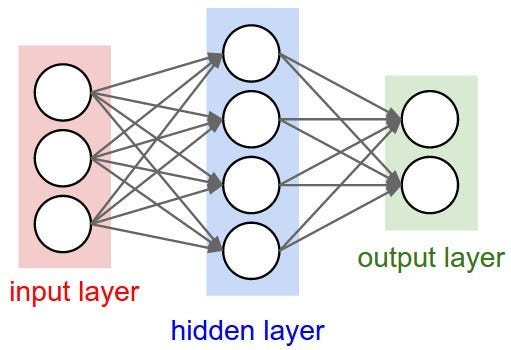
Here, the first layer W1X transforms the input data into hidden features. The max(0, .) part is called RELU(x) activation function — it mimics how neurons only fire when the input signal is strong enough. The second layer W2 converts those features into class scores.
Step 3: Going Deeper — The Power of Layers
Once we understood one layer, we naturally asked: what happens if we add more?
A three-layer neural network looks like this:
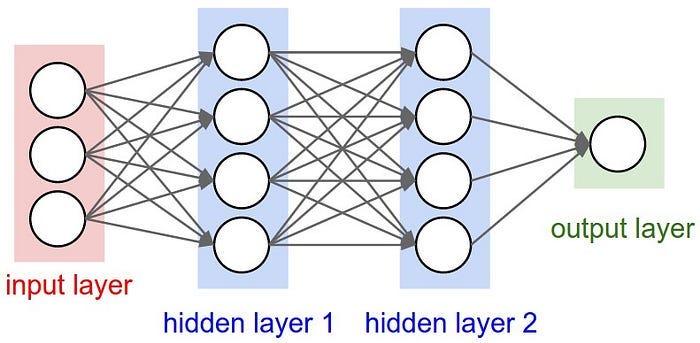
S = W3 *max(0,W2 *max(0,W1*X))
Each layer now extracts deeper and more abstract features. The first layer might detect edges or textures. The second could recognize shapes or parts of objects. The third might combine them into whole objects — like a “cat” or “car”.
Step 4: How Networks Learn — Backpropagation
After making a prediction, the network measures its error and then works backward to adjust each weight — one step at a time — using gradient descent. Every wrong prediction teaches the network a bit more. Over thousands of examples, it gradually gets better — just like how we learn from our mistakes.
Outcome
By understanding neural networks through the lens of perceptrons and the brain analogy, we gained a clear mental picture of how machines think:
• Neurons = Perceptrons: Both receive, weigh, and transmit signals.
• Synapses = Weights: The stronger the connection, the more influence that input has.
• Learning = Adjusting Weights: Just as human brains strengthen or weaken connections through experience.
• Non-linearity = Intelligence: Without it, the network would be as limited as a straight line on a graph.
Lessons Learned
• Think biologically, understand mathematically.
• Non-linearity is the secret sauce.
• Every weight matters.
• Depth brings abstraction.
• Learning is repetition.
• Simplicity wins
Conclusion
Understanding neural networks no longer feels like understanding magic. It feels like discovering a different kind of mind — one built from logic, not biology. Machines don’t dream or feel, but they do learn — through data, repetition, and feedback, much like us. We began this journey with confusion and curiosity, but now we see deep learning as a story — a story of how simple mathematical functions, inspired by the human brain, can lead to incredible intelligence.