



Bringing Intelligence Closer: Personalization and Computation at the Edge
In today’s world of global web applications, speed and proximity defines user experience. While cloud computing solved scalability, it didn’t fully solve latency — especially when users are far from the origin server. A request from India to a US-based server, for instance, can take hundreds of milliseconds even before processing begins.
That’s where AWS Lambda@Edge comes in.
It allows developers to run serverless functions at AWS edge locations, directly integrated with AWS CloudFront, enabling personalization, routing, and security logic to execute milliseconds away from the user — no servers, no maintenance, and no regional boundaries.
Understanding AWS Lambda@Edge
AWS Lambda@Edge extends AWS Lambda’s serverless capabilities to the edge network — a global layer of AWS data centers called CloudFront edge locations. It lets you run lightweight Node.js or Python code in response to CloudFront events, such as:
A viewer making a request
CloudFront fetching content from an origin
A response being returned to the viewer
These edge functions run close to the user, which means:
Lower latency
Real-time request/response manipulation
No dependency on the origin region
Built-in scalability (managed by AWS automatically)
In simpler terms:
“Lambda@Edge is serverless computing distributed globally.”
How Lambda@Edge Works
Lambda@Edge attaches directly to a CloudFront distribution and runs in response to specific lifecycle events:
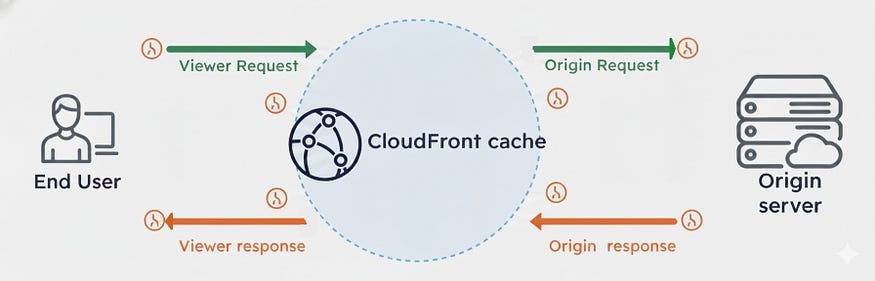
01. Viewer request :- When a Viewer Request event occurs, the function runs as soon as a user’s request reaches CloudFront — even before checking the cache. This is ideal for operations like URL rewrites, authentication, or redirecting users based on region or headers.
02. Viewer response:- This event is invoked right before CloudFront returns the final response to the viewer. This is where functions commonly add security headers, cookies, or even inject personalized content directly into the response body.
03. Origin request:- The origin request event triggers just before CloudFront forwards the request to the origin server. It’s useful for injecting or modifying headers, cookies, or query parameters that control caching or request routing.
04. Origin response:- This event runs after the origin has sent a response but before CloudFront caches it. This event stage is useful to compress data, sanitize responses, or adjust caching headers dynamically.
Together, these stages give developers complete control over how data flows between users and origins, all in real time.
How We Can Use Lambda@Edge in Practice
Lambda@Edge isn’t just about reducing latency — it’s about making edge nodes intelligent.
Here are use cases with example functions:
01. Geo-Targeted content delivery
Serve content relevant to the user’s region instantly — no origin call required. Useful in localizing landing pages, region-specific deals, GDPR or geo-blocking compliance.
02. Authentication and Authorization
Before a request even reaches your application server, Lambda@Edge can verify credentials or inject security headers. Which helps in token validation, API key verification, bot blocking, or implementing a “zero-trust” edge layer.
03. Dynamic Personalization
Deliver contextual experiences in milliseconds — such as showing user names, themes, or recommendations.
04. SEO and URL Rewriting
Search engines prefer clean, structured URLs. Lambda@Edge can rewrite or normalize URLs before they hit the origin.
05. Security and Compliance
Add or modify headers to enforce stricter browser policies, Strengthening security posture at the network edge.
06. Cache Key Optimization
By customizing cache keys, Lambda@Edge can decide when content should or shouldn’t be cached — boosting performance and reducing origin hits.
07. A/B Testing and Features Rollouts Run
Run experiments at the edge without changing backend routes or APIs. Which helps while Rolling out new features or layouts to a subset of users.
Set Up and Deploy AWS Lambda@Edge
Before following the setup steps, you’ll need an AWS CloudFront distribution. Lambda@Edge is tightly integrated with CloudFront, so the function will be associated with that distribution.
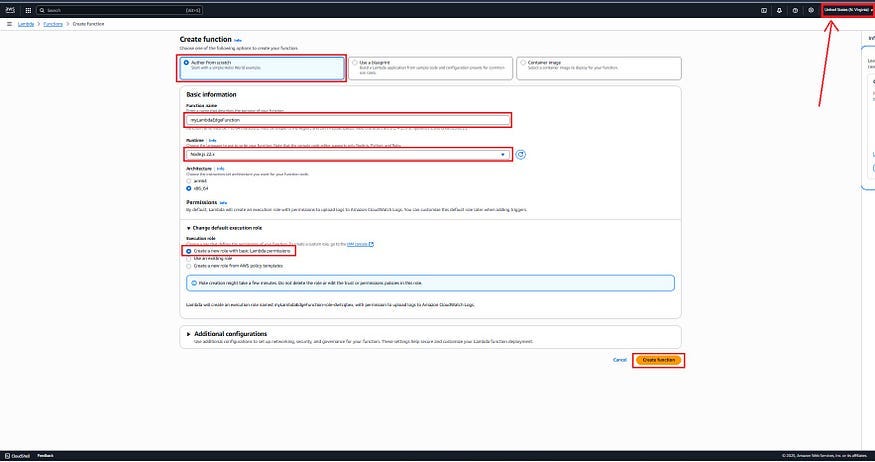
1. Go to the AWS Lambda console and create a new function in the US East (N. Virginia) region (us-east-1). Select Author from scratch, choose Node.js or Python, and assign the Basic Lambda@Edge permissions policy.
2. Once the function is created, open it in the console and either:
Upload your code file (index.js), or
Edit the inline code editor directly to paste your Lambda@Edge logic.
Then, click Deploy to save and publish your function code.
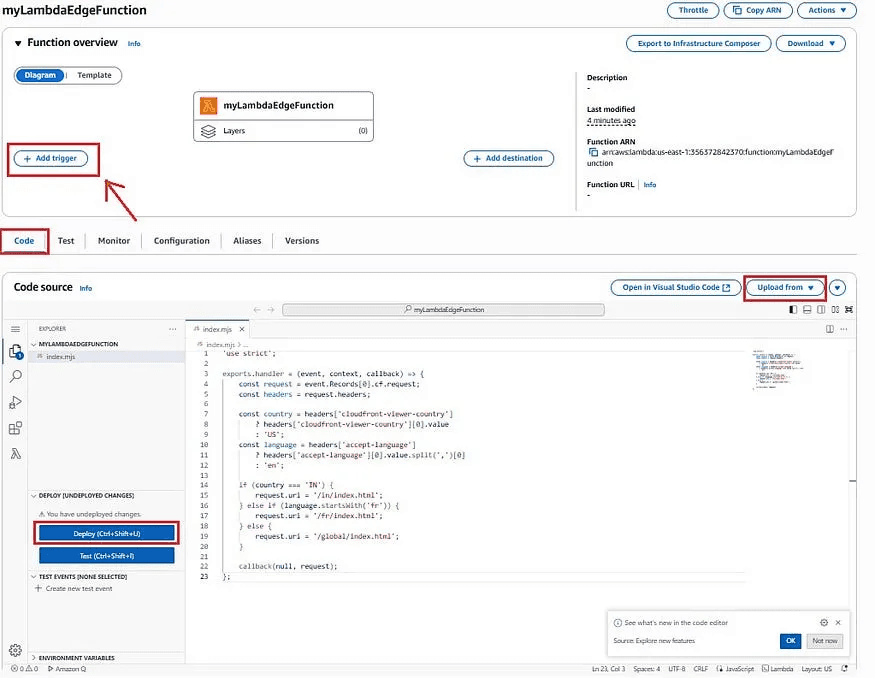
3. In the function overview, choose Add trigger. Select CloudFront as the trigger and click Deploy to Lambda@Edge.
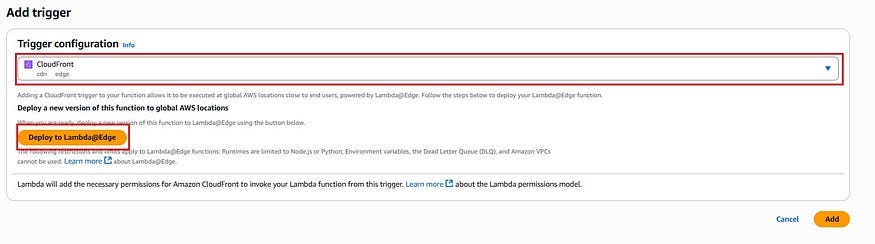
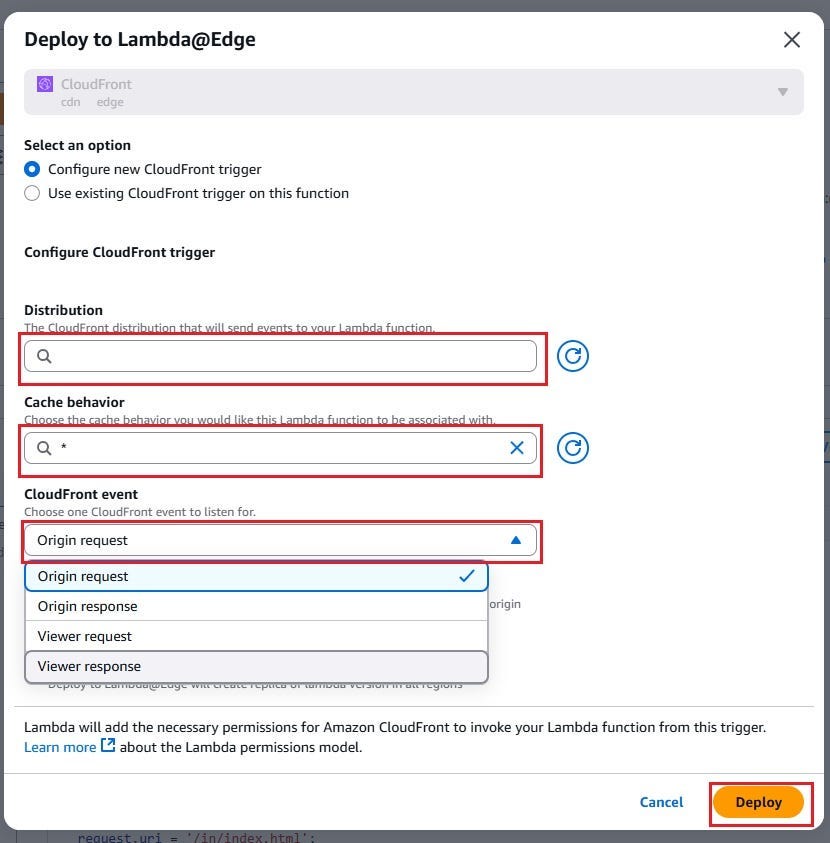
4. Pick your CloudFront distribution, choose the cache behavior, and select the event type (Viewer Request, Viewer Response, Origin Request, or Origin Response) that should trigger the function.
5. After deployment, AWS automatically replicates your function to edge locations worldwide.
6. Access your CloudFront URL to verify the function execution. Use AWS CloudWatch Logs to monitor performance or troubleshoot any errors.
Best Practices for Production
Keep logic minimal and stateless.
Use CloudFront cache behaviors strategically.
Combine Lambda@Edge with S3 + CloudFront for static web personalization.
Monitor logs using CloudWatch Metrics and Insights.
Always test functions in staging CloudFront distributions before global deployment.
Limitations and Considerations
Before using Lambda@Edge, keep these in mind:
Deployment Region: Only deployable in
us-east-1Package Size: ≤ 1 MB (zipped, including dependencies)
Runtime: Node.js & Python only
Execution Time: 5 seconds max
No Environment Variables: Unlike standard Lambda
Cold Starts: Rare but possible
Limited Debugging: Use CloudWatch logs only
Key Takeaways
Lambda@Edge brings computation closer to users, enabling low-latency and high-performance experiences across global regions.
It allows real-time personalization, routing, and security directly at AWS edge locations without depending on backend servers.
To maximize efficiency, keep functions lightweight, stateless, and latency-optimized, since runtime and package size are limited.
As edge computing continues to evolve, AWS Lambda@Edge stands as a cornerstone for building faster, smarter, and more responsive web applications.
Conclusion
AWS Lambda@Edge enables developers to run serverless logic globally without managing infrastructure and lets them deliver personalized, secure, and fast web experiences, with simplified backend workloads while cutting latency.